
In this article, we explore a Parallel Binary Tree Search implementation that leverages both CUDA and OpenMP to achieve high-performance computing. Binary tree search is a fundamental algorithmic technique, and by parallelizing it, we can dramatically reduce computation time, particularly for large datasets.
To accomplish this, we rely on two powerful technologies: OpenMP and CUDA.
OpenMP (Open Multi-Processing) is a widely used API that facilitates shared-memory parallel programming in C, C++, and Fortran, enabling developers to write parallel code efficiently through compiler directives, library routines, and environment settings. CUDA (Compute Unified Device Architecture), developed by NVIDIA, provides a platform for general-purpose computing on GPUs. By harnessing the massive parallelism of NVIDIA GPUs, CUDA allows complex computations to be performed far more rapidly than on traditional CPUs.
In the following sections, we will introduce the core concepts behind the parallel binary tree search, explain how to implement it using these tools, and discuss the performance benefits of combining CPU- and GPU-based parallelism.
The Idea Behind
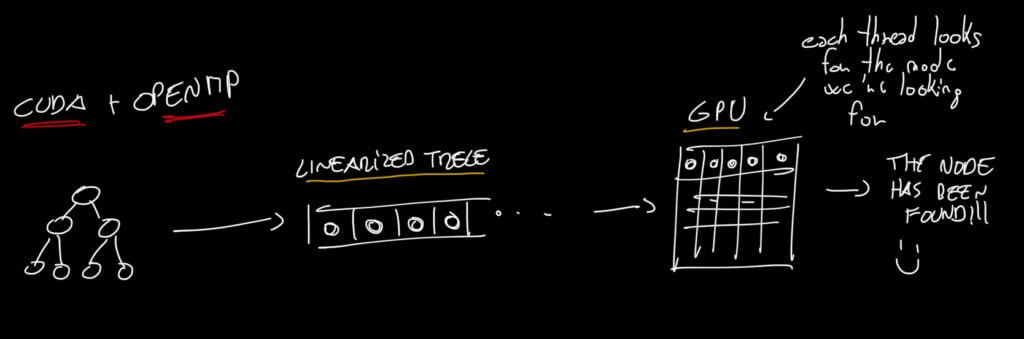
Before diving into the Parallel Binary Tree Search, it is important to understand the underlying concept. In the first step, we use OpenMP to linearize the binary tree into a simple array, extracting each node from the tree and placing it sequentially in the array.
In the subsequent step, this array is processed using CUDA, where each GPU thread is assigned the task of searching for the node containing the desired key. This combination of CPU-based parallelization with OpenMP and GPU-based parallel search with CUDA enables efficient exploration of the tree structure.
Implementation
Now, let’s focus on the code itself. In this section, I will highlight the key functions I implemented, which essentially drive the behavior I previously outlined in the sketch.
inOrder function
The tree-to-array conversion is implemented using an iterative in-order traversal with a stack. The traversal begins at the root node and uses a stack to temporarily store nodes while exploring left subtrees:
struct Node* current = root;
struct sNode* s = NULL;
bool done = 0;Each node is visited in a left-root-right sequence. If a left child exists, the current node is pushed onto the stack before moving to the left subtree:
if (current != NULL) {
push(&s, current);
current = current->left;
}When a leaf or null child is reached, the algorithm backtracks by popping a node from the stack, recording it in the nodesArray, and updating the currentIndex to ensure proper insertion order:
else {
if (!isEmpty(s)) {
current = pop(&s);
nodesArray[*currentIndex] = *current;
(*currentIndex)++;
current = current->right;
}
else
done = 1;
}This iterative approach avoids recursion, providing better memory control and simplifying debugging. Once the traversal is complete, the binary tree is fully linearized into nodesArray, preserving the in-order sequence of nodes. This array can then be passed to CUDA, where GPU threads perform parallel searches for specific keys, combining CPU-based preprocessing with GPU-based high-performance computation.
cudaSearch function
The core of the Parallel Binary Tree Search is implemented in the CUDA kernel cuda_search. Each GPU thread is responsible for examining a single element of the data_array and comparing it with the searched key. The thread calculates its unique global index using the block and thread IDs:
int index = threadIdx.x + blockIdx.x * blockDim.x;This ensures that each node in the array is checked exactly once. The thread first verifies that its index is within bounds to avoid accessing invalid memory:
if (index < num_nodes) {
struct Node *p = &data_array[index];Each thread then performs a comparison between the node’s key and the target key stored in d_searched_node.key. The result of this comparison is written into the result array:
int cmp_result = (p->key == d_searched_node.key) ? 1 : 0;
result[index] = cmp_result;
}If the keys match, 1 is written; otherwise, 0 is stored. This simple but effective mechanism allows massive parallelism: hundreds or thousands of threads simultaneously search different nodes, drastically reducing search time compared to a sequential CPU implementation.
getNodesByResult function
After the CUDA kernel has populated the h_result array, the next step is to traverse this array to locate the first match — the index where a node was successfully found. This is handled by the getNodesByResult function. First, we initialize a pointer that will eventually point to the matching node:
struct Node* finded_node = NULL; // Initialize node to return
To accelerate the search through the array, we can leverage OpenMP to parallelize the for loop. Each thread inspects a portion of the h_result array independently:
#pragma omp parallel
{
#pragma omp for
for (int i = 0; i < num_of_nodes; i++) {Within the loop, we check if the current element indicates a match (i.e., its value is 1). If so, we store the corresponding node’s address from the nodesArray:
if (h_result[i] == 1) {
finded_node = &nodesArray[i];
}Once all threads complete their work, the function returns the pointer to the found node. If no match was detected, it returns NULL:
}
}
return finded_node; // If no match is found, returns NULLThis approach ensures that we efficiently locate the first successful match in parallel, taking advantage of multi-core CPUs while keeping the code simple and robust.
In the Parallel Binary Tree Search, an in-order traversal using a stack was employed to visit the tree. This method is more memory-efficient than the commonly used recursive version, particularly when handling large data structures. Recursion can exceed the call stack limit, which could occur with a very large number of nodes. In the measurements, up to one million nodes were processed, and further increases could risk breaking the code due to insufficient stack memory for recursive calls.
For the CUDA implementation, in addition to global memory, constant memory was used to store the node being searched. Since this information is identical for all threads, the use of constant memory provided additional performance advantages.
Performance
Now, let’s move on to the most interesting part of the article: Performance. We will analyze performance across different parameters (in Italian, “Numero Threads” corresponds to “Number of Threads”). The measurements were carried out in two scenarios:
- Using integer keys for instant comparisons.
- Using more computationally demanding alphanumeric keys, which require longer comparison times.
Note: The results were also compared across different optimization levels provided by the C compiler. In this case, the best performance was achieved with the O2 optimization level. The experiments used BlockSize = 1024 and GridSize = ((num_of_nodes – 1) / blockSize.x + 1).
Another important aspect to describe the environment in which the measurements were conducted. For this experiment, I used Google Colab, with the following specifications at the time the measurements were taken.


Experiment with Integer Keys
Let’s begin by analyzing the performance of our algorithm using integer keys as the number of nodes changes.




We observed that, in general, as the number of nodes increases, the speedups are not always dramatic, although some are noteworthy. This occurs because, with more nodes and a wider “thread blanket,” more nodes can be processed in less time. Consequently, we can expect that as the number of nodes grows, the node search will become increasingly efficient.
Note: For consistency, in both cases, a node located roughly in the middle of the tree was chosen.
Experiment with AlphaNumeric Keys
Now, let’s consider the case where the key comparison is not a simple integer comparison (which is almost instantaneous). Instead, the keys require a more complex type of check. This adds extra time whenever the key being searched and the current node do not match, forcing additional tree traversal and further comparisons.

In general, classical binary tree searches have a time complexity of O(log n), whereas our approach requires significantly more time due to the additional operations performed. However, a noticeable performance difference emerges when comparing non-trivial keys in trees with a large number of nodes. This suggests that our method can be particularly advantageous when dealing with such “challenging” keys.
In conclusion, CUDA programming proves particularly effective when many threads are required to perform the same task with different parameters in parallel. This highlights the advantages of GPU computing for tasks involving large-scale parallelization.