
The automatic detection of malicious software represents one of the central challenges in contemporary cybersecurity. The continuous evolution of obfuscation, packing, and polymorphic mutation techniques has progressively reduced the effectiveness of traditional signature-based methods. In this context, the adoption of machine learning techniques has opened new perspectives but has also highlighted structural limitations when applied to overly simplistic representations of binary code.
This work presents a comprehensive and detailed description of the design and implementation of a Static Aalysis with GNN-based Malware Classifier to classify malware/benign executables. The underlying idea is that an executable program is not merely a linear sequence of bytes, but rather a complex structure governed by control and dependency relationships that can be naturally modeled as a graph.
The objective is not only to propose a high-performing model but also to outline a complete end-to-end pipeline: from the secure conversion of the binary into a structured representation, to feature design, rigorous experimentation, and integration into a real-world application system.
The problem of malware detection and the limitations of traditional approaches
Malware/benign classification is a supervised binary classification problem in which the objective is to learn a function capable of generalizing to previously unseen executables. Unlike many traditional machine learning contexts, this domain involves an active adversary: malware is intentionally designed to evade detection systems.
Traditional approaches can generally be divided into three main categories:
- Signature-based detection – matching against known malicious patterns or signatures.
- Static feature-based machine learning – the use of statistical features such as byte n-grams, opcodes, or metadata extracted from the Portable Executable (PE) structure.
- Dynamic analysis – observation of program behavior within controlled environments such as sandboxes.
Static approaches are generally efficient and scalable, but they often lose important structural information. Treating an executable purely as a sequence of bytes ignores the underlying control semantics of the program. Techniques such as packing and obfuscation can significantly alter the superficial representation of the binary while leaving its behavioral logic largely unchanged.
These limitations motivate the adoption of more robust representations capable of capturing the intrinsic structure of programs. In particular, structural representations such as the Control Flow Graph allow models to analyze relationships between different execution paths, providing a richer and more resilient basis for malware detection.
Graph Representation: the Control Flow Graph
A compiled executable can be disassembled into assembly instructions organized into basic blocks. A basic block is defined as a linear sequence of instructions without internal jumps, characterized by a single entry point and a single exit point. The relationships among these blocks are formally represented through a Control Flow Graph (CFG).
Within the CFG:
- Nodes represent basic blocks.
- Edges represent possible control transfers, such as conditional jumps, function calls, and returns.
This representation preserves several fundamental structural properties of the program, including the complexity of conditional branches, the presence of loops, patterns of API calls, and the overall modularity of the code. Many malicious behaviors—such as encryption routines typically used in ransomware or suspicious chains of API calls—emerge as recurring structural patterns within the graph.
The conversion from binary code to CFG was performed using static analysis tools, prioritizing completeness and security. In particular, a pipeline based on static disassembly was adopted using frameworks such as angr, always operating in an isolated environment and without executing the analyzed code. This design choice favors reproducibility and security over raw processing speed.
Graph Neural Networks in a nutshell
Graph Neural Networks represent a family of models specifically designed to operate on graph-structured data. Unlike traditional neural networks, which typically assume regular data structures such as vectors or images, GNNs propagate information between nodes through local aggregation operations across graph neighborhoods.
The fundamental principle underlying these models is the iterative update of node representations through messages received from neighboring nodes. After multiple iterations, each node progressively incorporates information from an increasingly larger portion of the graph. A subsequent global pooling operation then allows the computation of an embedding representing the entire graph, which can be used for downstream tasks such as classification. A really good article about that can be found here.
Among the architectures considered in this work are:
- Graph Convolutional Network (GCN): based on normalized neighborhood aggregation, offering a simple and computationally efficient approach.
- Graph Attention Network (GAT): introduces attention mechanisms to weight the importance of neighboring nodes.
- Graph Isomorphism Network (GIN): highly expressive and closely related to the discriminative power of the Weisfeiler–Lehman test.
- GraphSAGE: designed for inductive learning and improved scalability.
The adoption of GNNs for binary analysis stems from their ability to learn structural patterns without requiring the data to conform to a regular representation. In particular, they enable the integration of local information—such as opcodes or characteristics of individual basic blocks—with global properties related to the topology of the Control Flow Graph (CFG).
Dataset and pipeline process
The construction of the dataset required particular attention in order to avoid information leakage and potential bias.
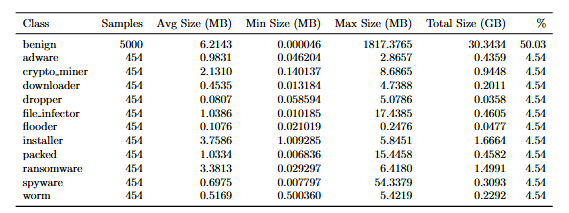
Malware and benign samples were collected from distinct sources, ensuring separation at the executable level between the training, validation, and test sets. The decision to operate directly on raw executables, rather than on pre-extracted features, allows for greater control over the processing pipeline and ensures independence from metadata that could potentially be manipulated. Further information about the dataset can be found in the table below.
The preprocessing pipeline consists of several stages designed to prepare executable files for graph-based analysis. These steps include:
- Validation of the file format and size.
- Parsing of the PE sections.
- Disassembly and function reconstruction.
- Construction of the Control Flow Graph (CFG).
- Extraction of node-level features Auto Encoder based.
- Serialization into a format compatible with PyTorch Geometric.
Security considerations were also incorporated into the system design. In particular, uploaded files are processed through staging in isolated environments, temporary files are automatically deleted after analysis, and resource usage is limited to reduce potential risks.
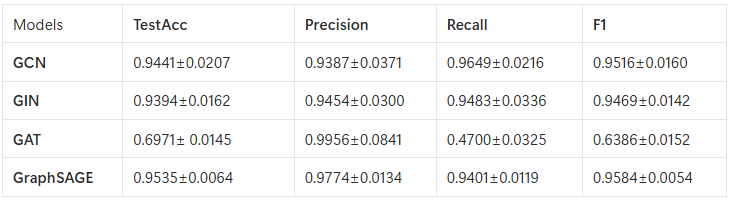
The following table reports the performance of the evaluated models according to the selected comparison metrics. The results are further enriched by the inclusion of the standard deviation, obtained through a k-fold cross-validation procedure, which provides an indication of the statistical stability and variability of the models across different training and validation splits.
The model
From the comparison among the evaluated architectures, GraphSAGE emerged as the best compromise between expressiveness, stability, scalability, and generalization capability. Its inductive nature allows the model to be applied to previously unseen graphs without requiring complete retraining, while the neighbor sampling mechanism reduces the computational burden when processing large graphs. The analysis of the standard deviation across the cross-validation folds highlighted a lower variance compared to more complex models such as Graph Isomorphism Network, indicating greater robustness.
The final classifier is composed of three GraphSAGE layers, followed by a global mean pooling layer, a final multilayer perceptron (MLP), and a two-class softmax output. Additionally, a dropout rate of 0.3 was applied to mitigate potential overfitting given the size of the dataset.
The inference pipeline handles the entire process, including file upload, conversion into a Control Flow Graph (CFG), feature extraction, forward pass through the model, and the return of a calibrated confidence score for the final prediction.
The system is integrated into a web application with a frontend built using Flask and a backend composed of the previously described analysis pipeline. The application also incorporates several security measures, including filename sanitization, temporary staging of uploaded files, worker isolation, and automatic deletion of analyzed files. Furthermore, the pipeline is designed in a modular manner, allowing the underlying model to be replaced without requiring modifications to the external interface.
The WebApp
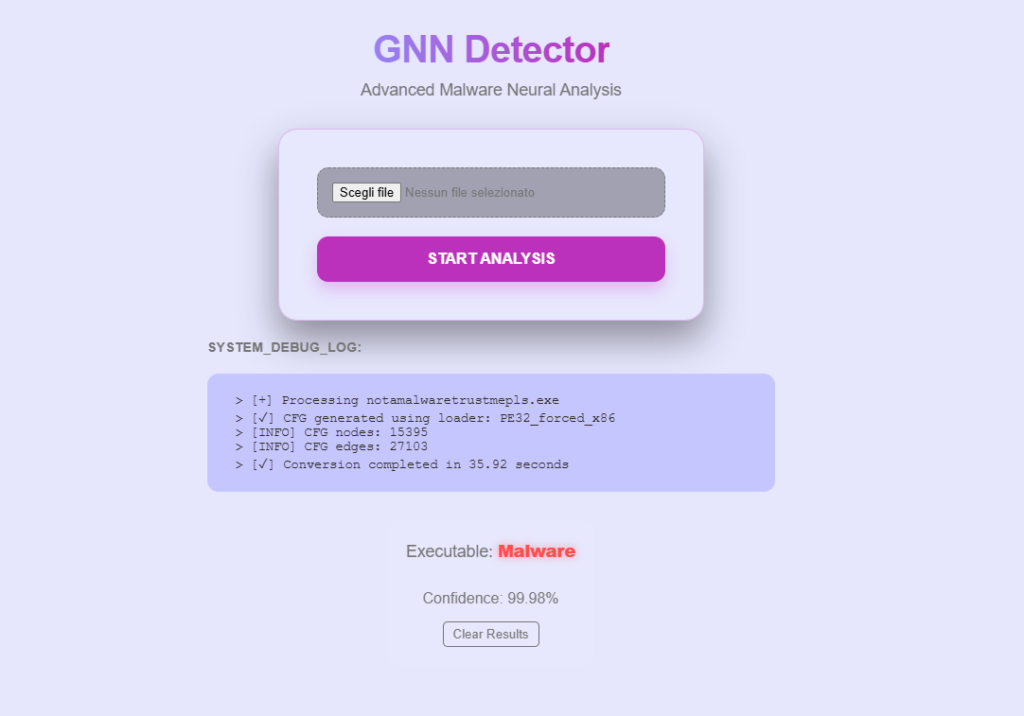
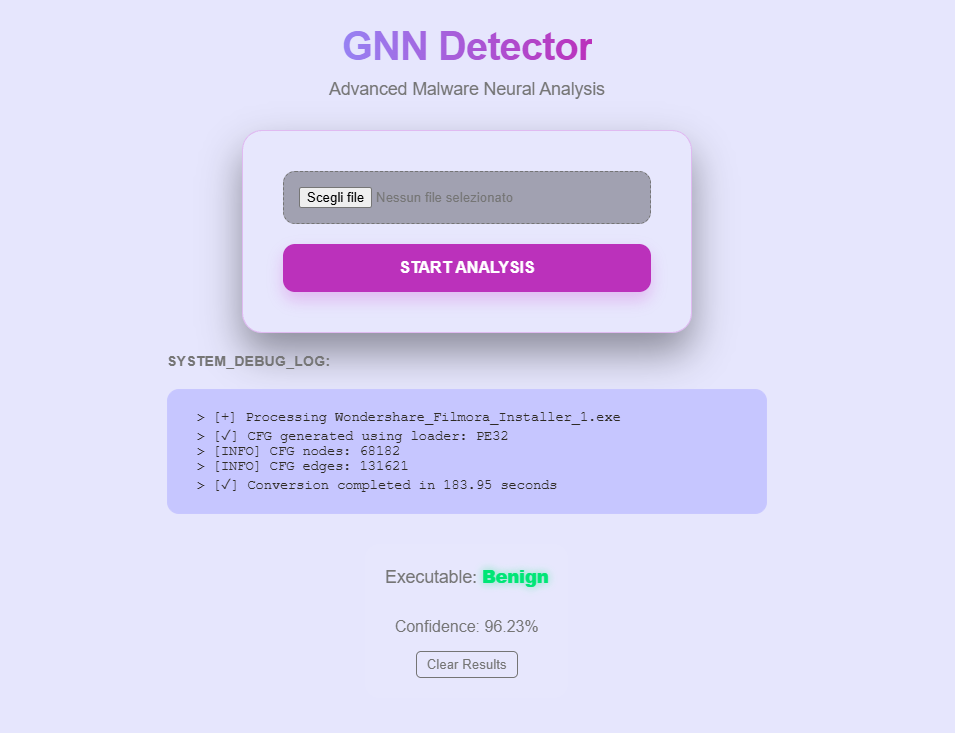
A web application was developed to demonstrate the practical usage of the proposed model. The application is implemented using Flask and provides a simple and intuitive user interface that allows users to upload an executable file for analysis.

During the upload and analysis process, the interface displays a sequence of debug logs that provide useful information about the extracted Control Flow Graph (CFG), including the number of nodes and edges, as well as the overall execution time required for the analysis. This logging mechanism allows users to observe the intermediate steps of the analysis pipeline in real time, improving transparency and interpretability of the system. Finally, once the analysis is completed, the application presents the predicted classification result together with a confidence score that indicates the reliability of the prediction produced by the model.
In conclusion, this work presented the design and development of a binary malware classifier based on graph representations of executable files. The study described the complete pipeline, starting from the preprocessing of executable binaries and the extraction of Control Flow Graphs (CFGs), followed by the construction of graph-based datasets and the training of deep learning models for malware detection. In particular, the adoption of Graph Neural Networks enabled the model to capture structural relationships within program execution flows, allowing a more informative representation of binaries compared to approaches that rely solely on raw byte sequences. The experimental evaluation demonstrated the effectiveness of the proposed approach through a systematic comparison with baseline models, highlighting the benefits of structured program representations for binary classification tasks. Finally, the implementation of a prototype web application based on Flask further demonstrated the practical applicability of the developed system, enabling users to upload executable files and obtain predictions in an accessible and transparent manner. Overall, the results confirm that graph-based learning techniques represent a promising direction for improving the accuracy and interpretability of malware detection systems.